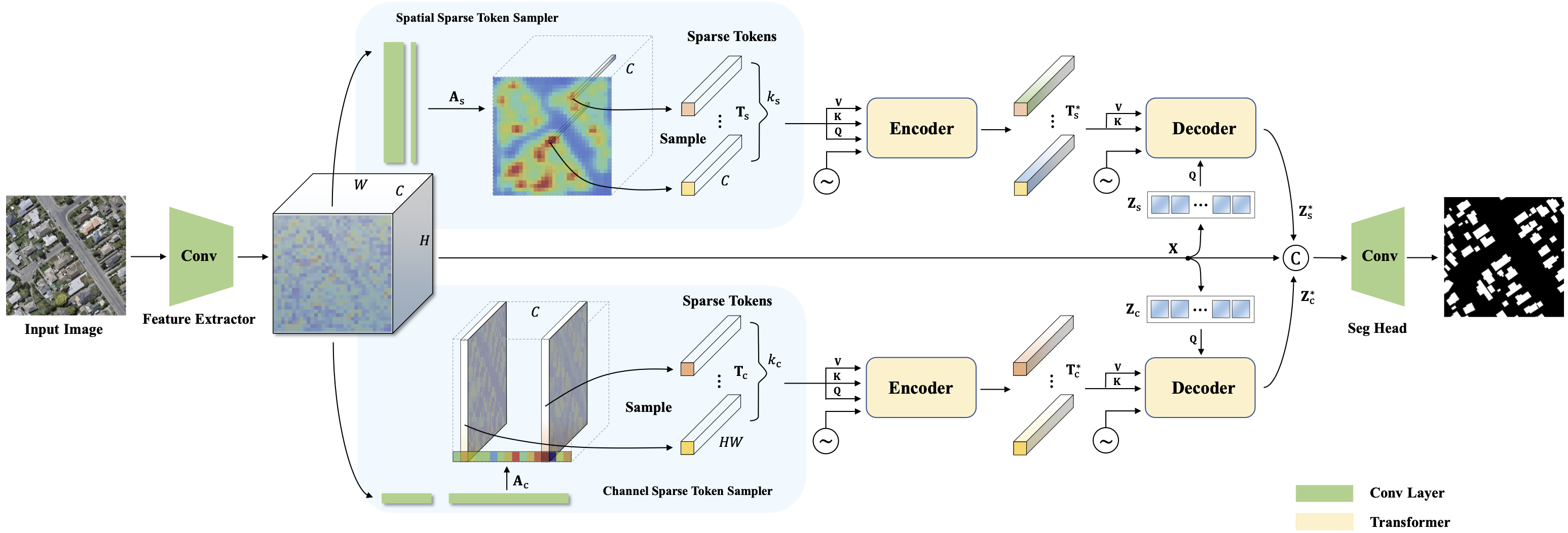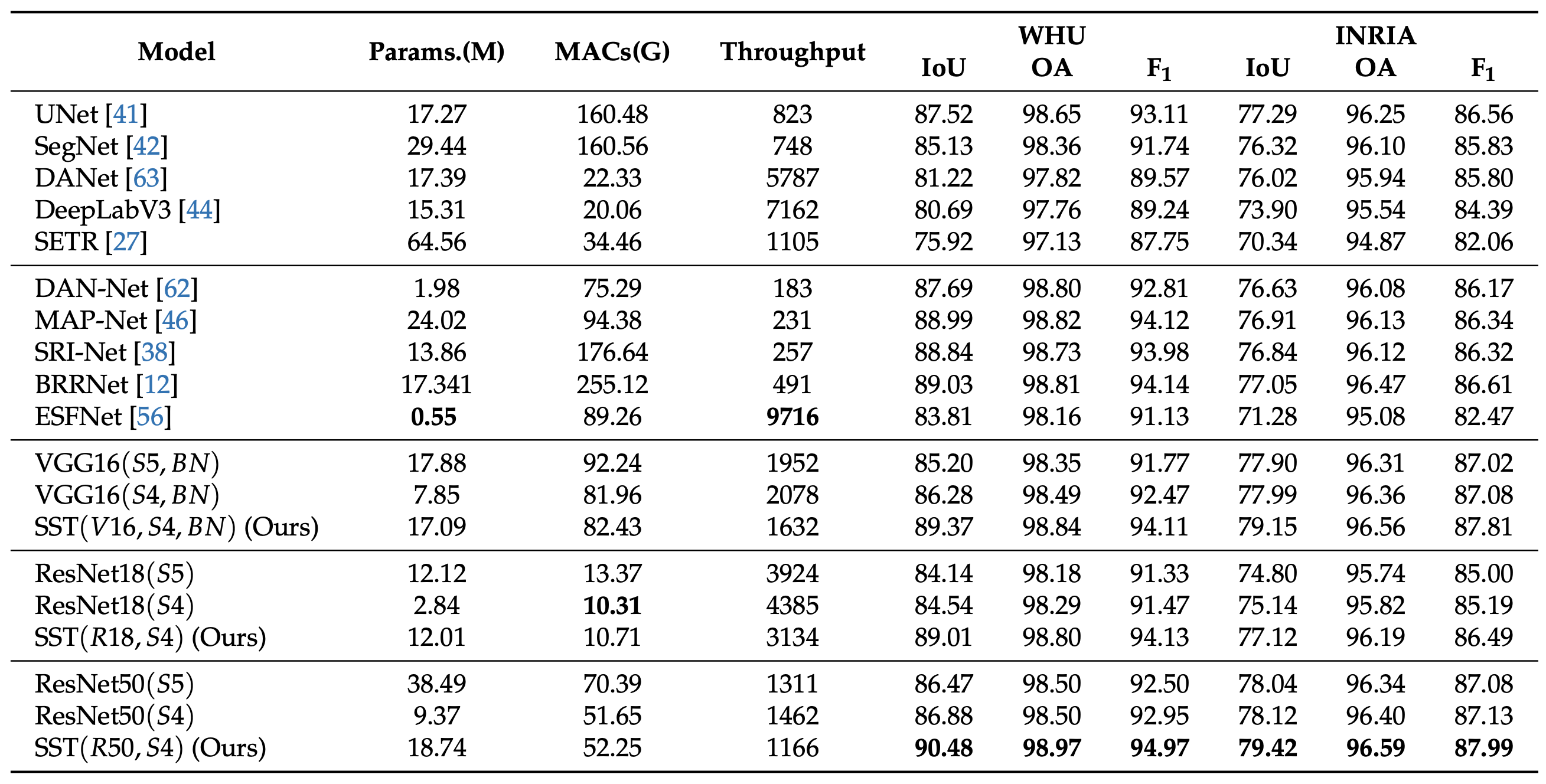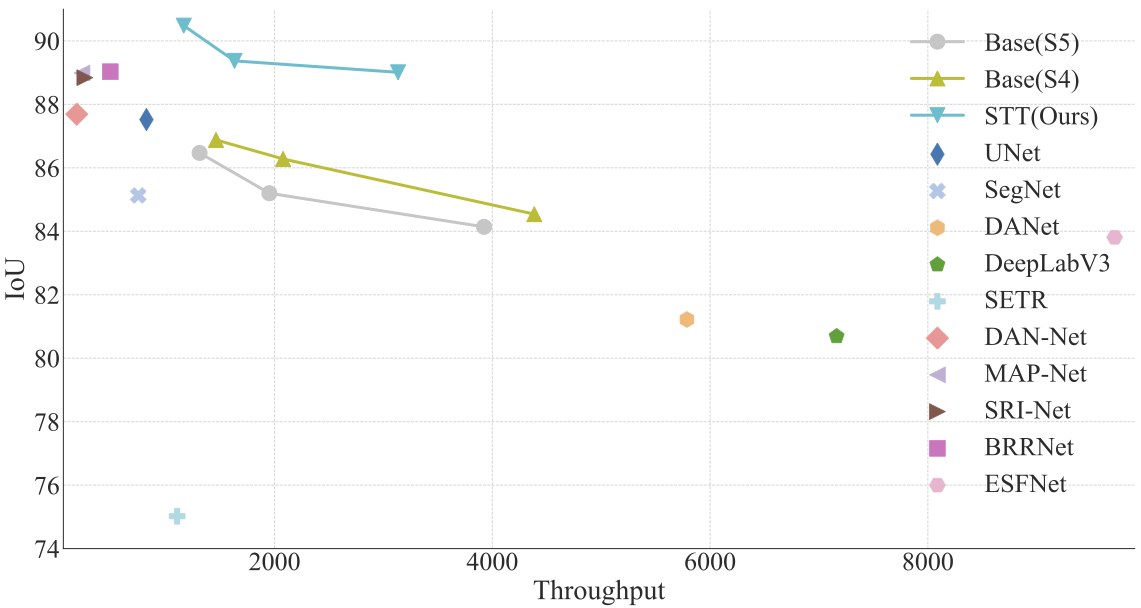
The Fig. shows the speed–accuracy trade-off and some comparable results between the proposed method and other state-of-the-art segmentation methods. Throughput (images with 512 × 512 pixels per second on a 2080Ti GPU) versus accuracy (IoU) on WHU aerial building extraction test set. Here, we only calculate the model inference time, not including the time to read images. Our model (SST) outperforms other segmentation methods with a clear margin. For STT, Base (S4), and Base (S5), points on the line from the left to the right refers to the models with different CNN feature extractor of ResNet50, VGG16 and ResNet18, respectively.